It is important for any organization to protect their critical data across physical, virtual, and cloud environments to minimize the risk of business disruption. If a disaster occurs, fast data restore and restart capabilities are required to ensure business continuity. So, replication is one of the ways to ensure the business continuity in case of any disasters.
Data Replication Techniques Overview
According to EMC definition, Replication is the process of creating an exact copy (replica) of the existing data. These replicas are used to restore and restart operations if data loss occurs because of any disasters or failures. For example, if a production server goes down, then the replica data can be used to restart the production operations with minimum disruption. The replicas can also be assigned to other servers to perform various business operations, such as backup, reporting, and testing.

Pic Credits - EMC
Based on the organisations data requirements, data can be replicated to one or more locations. For example, data can be replicated within a data center, between data centers, from a data center to a cloud, or between clouds. In a software-defined data center environment, organizations have policy-based automation of replication process.
Also Read: Data Migration and Disaster Recovery As a Service (DRAaS) Solutions
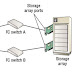
This policy-based automatic replications decide the number of replicas to be created and the location where the data should be stored. Typically, organizations providing cloud services have multiple data centers across the world and they can provide options to customers for choosing the location to which the data is to be replicated. Generally a production server access the data from one or more LUNs on storage systems. These LUNs are known as source LUNs, production LUNs, or simply the source. A LUN on which the production data is replicated to is called the target LUN or simply the target or replica.
Also Read: Data Migration and Disaster Recovery As a Service (DRAaS) Solutions
This policy-based automatic replications decide the number of replicas to be created and the location where the data should be stored. Typically, organizations providing cloud services have multiple data centers across the world and they can provide options to customers for choosing the location to which the data is to be replicated. Generally a production server access the data from one or more LUNs on storage systems. These LUNs are known as source LUNs, production LUNs, or simply the source. A LUN on which the production data is replicated to is called the target LUN or simply the target or replica.
Characteristics of Data Replication
- Recoverability - Enables restoration of data from the replicas to the source if data loss occurs.
- Restartability - Enables restarting business operations using the replicas.
- Consistency - Replica must be consistent with the source so that it is usable for both recovery and restart operations.
- PIT replica - The data on the replica will be an identical image of the production at some specific timestamp.
- Continuous replica - The data on the replica is in-sync with the production data at all times. The objective with any continuous replication is to reduce the RPO to zero or near-zero.
Consistency is a primary requirement to ensure the usability of replica device. In case of file systems, consistency can be achieved either by taking file system offline i.e. by un-mounting file system or by keeping file system online by flushing server buffers before creating replica. Server's memory buffers must be flushed to disks to ensure data consistency on the replica, prior to its creation. If the memory buffers are not flushed to the disk, the data on the replica will not contain the information that was buffered in the server.
Also Read: How storage is provisioned in Software Defined Storage Environments
Also Read: How storage is provisioned in Software Defined Storage Environments
Similarly in case of databases, consistency can be achieved either by taking database offline for creating consistent replica or by keeping online. If the database is online, it is available for I/O operations, and transactions to the database update the data continuously. When a database is replicated while it is online, changes made to the database at this time must be applied to the replica to make it consistent.
Replication Uses
- Replication can be used as an alternative source for backup. Under normal backup operations, data is read from the production LUNs and written to the backup device. This places an additional pressure on the production infrastructure because production LUNs are simultaneously involved in production operations and servicing data for backup operations. To avoid this situation, a replication can be created from production LUN and it can be used as a source to perform backup operations. This alleviates the backup I/O workload on the production LUNs.
- It can be used for fast recovery and restart. For critical applications, replicas can be taken at short, regular intervals. This allows easy and fast recovery from data loss. If a complete failure of the production LUN occurs, the replication solution enables one to restart the production operation on the replica to reduce the RTO.
- It can be used for generating reports. Running reports using the data on the replicas greatly reduces the I/O burden placed on the production device.
- It can be used for testing new business models. Replicas are also used for testing new applications or upgrades. For example, an organization may use the replica to test the production application upgrade; if the test is successful, the upgrade may be implemented on the production environment.
- Another use for a replica is data migration. Data migrations are performed for various reasons, such as migrating from a smaller capacity LUN to one of a larger capacity for newer versions of the application.
Types of Replication
Replication can be classified into local and remote replication.
- Local replication refers to replicating data within the same storage system or the same data center. Local replicas help to restore the data in the event of data loss or enable restarting the application immediately to ensure business continuity. Local replication can be implemented at server, storage, and network level.
- Remote replication refers to replicating data to remote locations. Remote replication helps organizations to mitigate the risks associated with regional outages resulting from natural or human-made disasters. During disasters, the services can be moved (failover) to a remote location to ensure continuous business operation. Remote replication also allows organizations to replicate their data to the cloud for DR purpose. In a remote replication, data can be synchronously or asynchronously replicated and can also be implemented at server, storage, and network levels.
What Others are Reading Now...


0 Comment to "12.1 Data Replication Techniques Introduction"
Post a Comment