The rapid adoption of next generation technologies like social media, big data analytics, cloud, and mobile application leads to significant data growth. Today, organizations not only have to store and protect petabytes and petabytes of data, but they also have to retain the data over longer periods of time, for regulation and compliance reasons.
In addition to increasing amounts of data, there has also been a significant shift in how people want and expect to access their data. The rising adoption rate of smartphones, tablets, and other mobile devices by consumers, combined with increasing acceptance of these devices in enterprise workplaces, has resulted in an expectation for on-demand access to data from anywhere on any device.
Also Read: File Based Storage Systems (NAS) Overview
These challenges demand a smarter approach (object storage) that allows to manage data growth at low cost, provides extensive metadata capabilities, and also provides massive scalability to keep up with the rapidly growing data storage and access demands.
Object storage is a new type of storage system designed for cloud-scale scalability. Objects are stored and retrieved from an object store through the web-based APIs such as REST and SOAP. Each object can be linked with extensive metadata that can be searched and indexed. Object storage is ideal for rich content data that does not change often and does not require high performance. It is popular in the public cloud model.

. The object ID is generated using specialized algorithms such as a hash function on the data and guarantees that every object is uniquely identified. Any changes in the object, like user-based edits to the file, results in a new object ID. Most of the object storage system supports APIs to integrate it with software-defined data center and cloud environments.
Also Read: Block Based Storage Systems (SAN) Overview
Unlike SAN and NAS, applications do not know the location of the object stored. With object storage, the application creates some data and give it to the OSD in exchange for a unique object id (OID). The application which created the data does not need to know where the object is stored as long as it is protected and returned whenever the application needed it.
For example, Consider a traditional car parking in any shopping mall or restaurant. It is your responsibility to remember where you have parked your car in the huge parking area. But now a days we have Valet parking, you just need to give your keys and you will have no idea where your car will be parked and they will bring it back to you when you needed it. Similarly in Object storage, the application will not know the location of the object but it can get it whenever it is needed.

The OSD node has two key services: metadata service and storage service. The metadata service is responsible for generating the object ID from the contents of a file. It also maintains the mapping of the object IDs and the file system namespace. In some implementations, the metadata service runs inside an application server. The storage service manages a set of disks on which the user data is stored.
OSD typically uses low-cost and high-density disk drives to store the objects. As more capacity is required, more disk drives can be added to the system.
Read: SAN vs NAS vs DAS
Also Read: File Based Storage Systems (NAS) Overview
These challenges demand a smarter approach (object storage) that allows to manage data growth at low cost, provides extensive metadata capabilities, and also provides massive scalability to keep up with the rapidly growing data storage and access demands.
Object storage is a new type of storage system designed for cloud-scale scalability. Objects are stored and retrieved from an object store through the web-based APIs such as REST and SOAP. Each object can be linked with extensive metadata that can be searched and indexed. Object storage is ideal for rich content data that does not change often and does not require high performance. It is popular in the public cloud model.
Object-based Storage Overview
Object-based storage device stores data in the form of objects on flat address space based on its content and other attributes rather than the name and the location. An object is the fundamental unit of object-based storage that contains user data, related metadata (size, date, ownership, etc.), and user defined attributes of data (retention, access pattern, and other business-relevant attributes).
The additional metadata or attributes enable optimized search, retention and deletion of objects. For example, when bank account information is stored as a file in a NAS system, the metadata is basic and may include information such as file name, date of creation, owner, and file type. When stored as an object, the metadata component of the object may include additional information such as account name, ID, and bank location, apart from the basic metadata.

. The object ID is generated using specialized algorithms such as a hash function on the data and guarantees that every object is uniquely identified. Any changes in the object, like user-based edits to the file, results in a new object ID. Most of the object storage system supports APIs to integrate it with software-defined data center and cloud environments.
Also Read: Block Based Storage Systems (SAN) Overview
Unlike SAN and NAS, applications do not know the location of the object stored. With object storage, the application creates some data and give it to the OSD in exchange for a unique object id (OID). The application which created the data does not need to know where the object is stored as long as it is protected and returned whenever the application needed it.
For example, Consider a traditional car parking in any shopping mall or restaurant. It is your responsibility to remember where you have parked your car in the huge parking area. But now a days we have Valet parking, you just need to give your keys and you will have no idea where your car will be parked and they will bring it back to you when you needed it. Similarly in Object storage, the application will not know the location of the object but it can get it whenever it is needed.
Components of Object based Storage Device
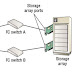
The OSD system is typically composed of three key components: Controllers, internal network, and storage.
Nodes (controllers)
The OSD system is composed of one or more nodes or controllers. A node is a server that runs the OSD operating environment and provides services to store, retrieve, and manage data in the system. Typically OSD systems are architected to work with inexpensive x86-based nodes, each node provides both compute and storage resources, and scales linearly in capacity and performance by simply adding nodes.

Internal Network
The OSD nodes connect to the storage via an internal network. The internal network provides node-to-node connectivity and node-to-storage connectivity. The application server accesses the node to store and retrieve data over an external network.
Storage
Difference between Objects, Files and Blocks
With the adoptation of Cloud in the organizations, object based storage is predominantly intended for cloud-scale and cloud-use cases as well as designed to be accessed via RESTful APIs. If we were to compare object storage to SAN or NAS storage, it would probably be fair to say that object storage has more in common with NAS than SAN. This is mainly because objects are more like files than they are blocks. In fact, it could be said that in many cases files are objects, and objects are files. However, there are several key differences between an object storage device (OSD) and a NAS system.Read: SAN vs NAS vs DAS
Traditional storage solutions like NAS, which is a dominant solution for storing unstructured data, cannot scale to the capacities required or provide universal access across geographically dispersed locations. Data growth adds high overhead to the NAS in terms of managing large number of permission and nested directories. File systems require more management as they scale and are limited in size. Their performance degrades as file system size increases, and do not accommodate metadata beyond file properties which is a requirement of many new applications.
Additionally, Objects don’t always have human-friendly names. They are often identified by complex long (for example, 64-bit) unique identifiers that are derived from the content of the
object plus some arbitrary hashing scheme. Next, objects are stored in a single, large, flat namespace. Flat means that there is no hierarchy or tree structure as there is with a traditional filesystem. This flat namespace is a key factor in the massive scalability inherent in object storage systems. Even scale-out NAS systems, with the massive petabyte-scale filesystems, limit the number of files in either the filesystem or individual directories within the filesystem.
Another key difference between object storage and NAS is that object storage devices are not usually mounted over the network like NAS filesystems using NFS and SMB/CIFS. Object storage devices are accessed through APIs suchas REST, SOAP and XAM.
Object storage is not designed for high-performance and high-change requirements, nor is it designed for storage of structured data such as databases. This is because object storage often doesn’t allow updates in place. It is also not necessarily the best choice for data that changes a lot. What it is great for is storage and retrieval of rich media and other Web 2.0 types of content such as photos, videos, audio, and other documents.
Previous: File Level Storage (NAS) Virtualization and Storage Tiering
Go To >> Index Page
File-based storage systems (NAS) are based on file hierarchies that are complex in structure. Most file systems have restrictions on the number of files, directories and levels of hierarchy that can be supported, which limits the amount of data that can be stored. Whereas Object based storage systems stores data using flat address space where the objects exist at the same level and one object cannot be placed inside another object. Therefore, there is no hierarchy of directories and files, and as a result, billions of objects are to be stored in a single namespace.
Additionally, Objects don’t always have human-friendly names. They are often identified by complex long (for example, 64-bit) unique identifiers that are derived from the content of the
object plus some arbitrary hashing scheme. Next, objects are stored in a single, large, flat namespace. Flat means that there is no hierarchy or tree structure as there is with a traditional filesystem. This flat namespace is a key factor in the massive scalability inherent in object storage systems. Even scale-out NAS systems, with the massive petabyte-scale filesystems, limit the number of files in either the filesystem or individual directories within the filesystem.
Another key difference between object storage and NAS is that object storage devices are not usually mounted over the network like NAS filesystems using NFS and SMB/CIFS. Object storage devices are accessed through APIs suchas REST, SOAP and XAM.
Object storage is not designed for high-performance and high-change requirements, nor is it designed for storage of structured data such as databases. This is because object storage often doesn’t allow updates in place. It is also not necessarily the best choice for data that changes a lot. What it is great for is storage and retrieval of rich media and other Web 2.0 types of content such as photos, videos, audio, and other documents.
Previous: File Level Storage (NAS) Virtualization and Storage Tiering
Go To >> Index Page
What Others are Reading Now...


0 Comment to "9.1 Object based Storage Systems Introduction"
Post a Comment